

Understanding CAP and Eventual Consistency in Distributed Systems

 May 03,2025
May 03,2025  By admin
By admin 
Introduction
Distributed systems must balance multiple goals. The CAP theorem (Brewer’s theorem) formalises this balance: in the presence of a network partition, a distributed system can guarantee only two of the following three properties at once. Consistency means every node sees the same data at the same time, Availability means every request to a working node receives a (non-error) response, and Partition Tolerance means the system keeps working despite network failures. In practice, network partitions are inevitable in any multi-node system. Thus, when a partition occurs, the system must choose whether to favour consistency or availability.
Consistency (C) in CAP means that after a write completes, all future reads will see that write. All nodes agree on the data. Availability (A) means every request to any non-failing node returns a response (success or failure), even if some nodes are down. Partition Tolerance (P) means the system continues to operate despite arbitrary delays or loss of messages between nodes.
But simply: you can only have two of the three C, A, and P. For example, if a network partition splits the cluster, you must either delay responding to some requests (sacrifice availability) in order to keep all replicas consistent, or return potentially stale data (sacrifice consistency) while remaining available. No system can avoid this dilemma.
CAP Trade-Offs: CP, AP, CA
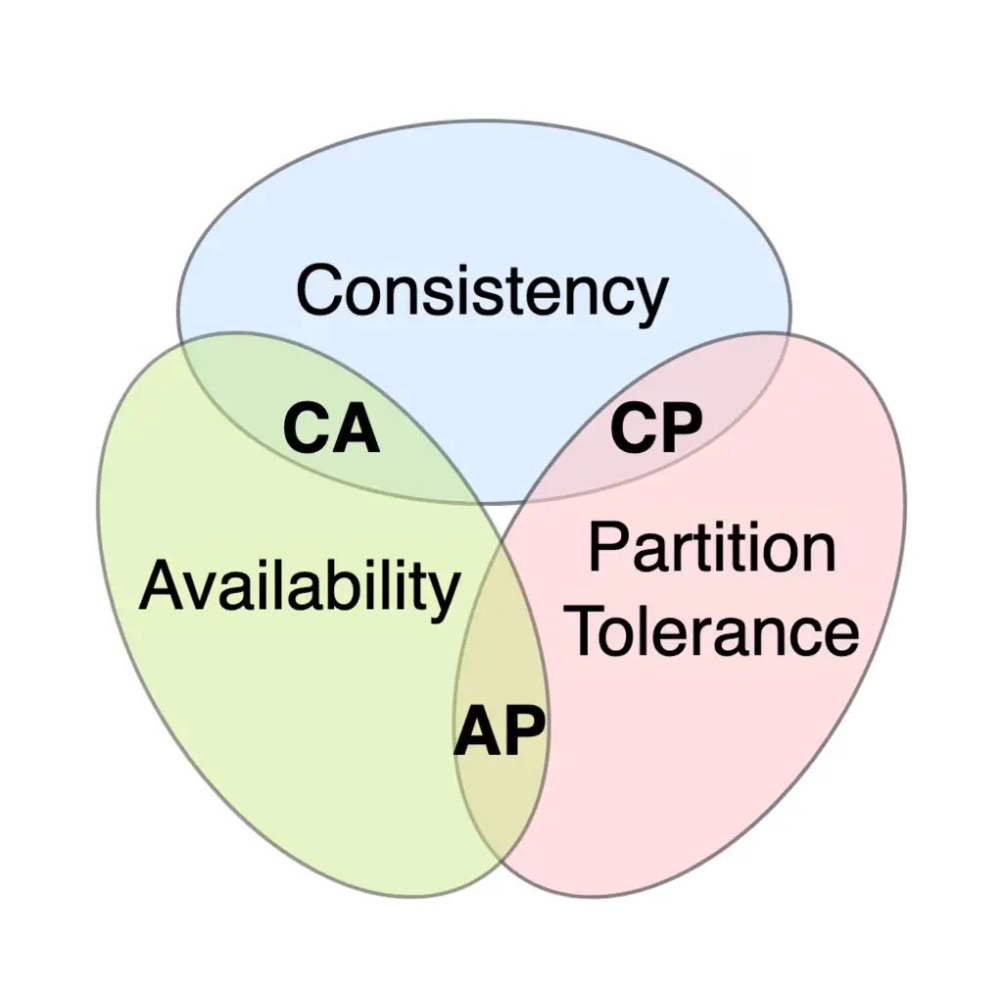
Architects categories systems by which two guarantees they priorities. A CP system (Consistency + Partition Tolerance) enforces that all nodes agree on data even during failures. In a CP design, writes are not considered successful until they are replicated to all nodes, so reads always see the latest value. This means that under a network split, a CP system may sacrifice availability (some nodes go offline or reject requests) to maintain consistency. MongoDB (in its default single-master replica-set mode) is often cited as effectively CP: it resolves partitions by electing a new primary and holds off writes during a split. In a CP database like Google’s Spanner or Bigtable, consistency is paramount even if some clients temporarily can’t write or read data.
An AP system (Availability + Partition Tolerance) keeps the service up and running even during network failures, at the expense of strict consistency. AP databases allow reads and writes to succeed on whichever nodes are reachable; they may return stale data, but they never refuse a request as long as any partition of the cluster is available. Classic AP examples include Amazon’s Dynamo (and DynamoDB) and Cassandra. These systems are masterless and use replication and quorum techniques so that any node can answer requests. When a network split occurs, they keep answering queries, but different nodes may have different versions of the data. Updates are reconciled later (often by read-repair or hinted handoff) to achieve eventual consistency. For instance, Cassandra allows clients to tune consistency: a write to a single node is the fastest and most available choice (AP), while requiring a quorum of nodes makes it slower but more consistent.
A CA system (Consistency + Availability) would provide both consistency and availability, but without true partition tolerance. In practical terms, a CA system can only exist if network partitions never occur. For example, a single-server database or a tightly coupled cluster behind a reliable failover mechanism might act as a CA. Traditional relational databases (e.g. a primary-secondary PostgreSQL cluster without split-brain protection) aim for CA: they replicate data and serve reads/writes consistently, but if a partition occurs, they cannot continue without risking split-brain. As IBM notes, many relational databases deliver consistency and availability across replicas, but this only works when you can ignore partitions. In real geographically distributed systems, CA is usually impossible without extraordinary measures (GPS clocks, etc.), so in practice, architects almost always accept partition tolerance and trade off C vs. A.
When a system sacrifices strict consistency (the “C” in CAP) to stay available, it often adopts an eventual consistency model. This is common in AP databases. Eventual consistency guarantees that if no new updates are made, all replicas will converge to the same state eventually. In other words, writes are accepted quickly on some nodes, and replicas propagate updates asynchronously. During the convergence window, reads may return stale (older) values. Eventual consistency enables high availability: the system can keep serving reads and writes without coordination, but it does not promise that a read will immediately reflect the latest write. As one source explains, prioritising availability “often means relaxing strict consistency requirements, leading to eventual consistency where different nodes may temporarily hold different versions of the data”.
For example, Amazon DynamoDB by default uses eventually consistent reads for speed: after writing a value, if you read it immediately from another node, you might get the old value. Eventually (within seconds, depending on propagation and replication), all copies converge. However, many systems offer tunable consistency. DynamoDB lets you request a strong (linearizable) read when needed. Cassandra similarly supports tunable consistency: you can require a read or write quorum (majority of replicas) for stronger consistency, or a single node for maximum availability. In a high-availability setup, writes to different replicas include timestamps or vector clocks, and the system uses techniques like “read-repair” or conflict resolution (e.g. last-write-wins, merge functions) to reconcile divergent replicas. This means that under normal operation, an update will propagate through the cluster (often via gossip or hinted handoff) until all nodes agree, but the timing of that convergence is not guaranteed.
Designers choose databases or architectures based on these trade-offs. For CP examples (prioritising consistency), consider Google’s Bigtable or Spanner, which use synchronised clocks and tight protocols to give a consistent view of data across replicas. During a partition, these systems may block or reject writes to avoid inconsistency. MongoDB’s default mode is also effectively CP: it sacrifices availability during partition (only one primary serves writes, and elections ensure consistency). Some key-value stores (Redis with synchronous replication) also behave as CP in the CAP sense. These systems will guarantee that clients see the latest write, but they may become unavailable or write-only during failures. For AP examples (prioritising availability), Apache Cassandra and Amazon DynamoDB stand out. Cassandra runs without a single master, so any node can serve a request. On a partition, Cassandra will continue to accept reads and writes (using the most recent replica available), and resolve conflicts later. DynamoDB (the managed successor to Amazon’s Dynamo) similarly offers “eventually consistent reads” by default for performance, although it also gives an option for strong consistency. Apache CouchDB and Riak are other AP systems; they use multi-version concurrency (MVCC) or vector clocks to reconcile divergent updates. Typically, these systems emphasise low latency and high uptime. As one source notes, CouchDB, Cassandra, and ScyllaDB are examples of AP databases. In practice, developers set up such systems to be fully partition-tolerant and mostly available, accepting that reads might return old data for a short time. Mixed or Tunable Consistency: Many modern databases let you tune the trade-off. For example, Cassandra clients specify a consistency level per query (e.g. quorum reads/writes for stronger consistency, or “ANY”/single node for availability). DynamoDB lets you choose between eventual or strongly consistent reads. MongoDB can read from secondaries (eventual reads) or only from the primary (strong reads). This flexibility means a system is not strictly one corner of the CAP triangle but can slide between. For instance, ScyllaDB and Cassandra can be AP for most operations, but critical reads/writes can use a quorum (making them CA for that operation). In summary, some popular distributed systems illustrate the points above:
- CP Systems (favour consistency): Google Spanner/Bigtable, MongoDB (primary-secondary replication), relational DB clusters (PostgreSQL, MySQL clusters without split-brain.
- AP Systems (favour availability): Apache Cassandra, Amazon DynamoDB, CouchDB, Riak, Elasticsearch (with replication).
- CA Systems (no partition tolerance): Single-node databases or tightly coupled replicas (e.g. a PostgreSQL primary-secondary cluster with synchronous replication). These can appear both consistent and available, but they break under real network partitions (thus lacking P).
The CAP theorem is a foundational guideline for distributed system design. It reminds us that under failure (network partitions), we must sacrifice either consistency or availability. Systems that emphasise availability over consistency use eventual consistency to converge in the background, while those that emphasise consistency may become unavailable until replicas synchronise. Real-world databases navigate these trade-offs differently: for example, Cassandra and DynamoDB prioritise availability, using eventual consistency, whereas MongoDB and Spanner prioritise consistency. There is no single “best” choice – architects must weigh application requirements (e.g. tolerating stale reads vs. requiring always up-time) and use the CAP principle to guide their design. By understanding CAP and consistency models (and visualizing them with diagrams like the CAP triangle or consistency timelines), system architects can make informed decisions for building robust, scalable distributed services.
Authored by : Rushikesh Saraf




